
This is cross-posted from the WorkWhile engineering blog.
This post describes a data pipeline we built to convert an analytical SQL query into an aggressively cached JSON API with zero load on our database or application.
Contents
Motivation
WorkWhile is the labor marketplace of the future. Our Econ Lab is on a mission to harness the large corpus of data generated on our labor platform to create new insights about the state of this emerging economy as well as the overall U.S. economy. As part of this mission to unlock insights, we recently launched a new economic index ALUR that measures labor force utilization1 and a group of economic indicators RISE that measure directional trends in wage data.
As part of socializing these new economic metrics, we went all out and showcased them on billboards from Times Square to San Francisco's financial district to the Las Vegas strip. With that level of visibility, we'd need to serve these metrics a lot and maintain a real-time feed to track any changes to these over time.
Core problem

These time series help provide insight on a daily or monthly basis into ever-changing economic conditions. Computing and aggregating these values requires significant work from our database, but it's work that is largely static. In particular, "past" data is unlikely to ever change, and "current" data (i.e. current day and preceding few days) is only being updated marginally.
Querying the production database2 directly would result in high latency and heavy load due to repeated execution of an expensive query. While these metrics originate from our core application data, this isn't a user-facing feature3; it's a data product. That's why we chose not to serve this request AT ALL from our primary application infrastructure.
Cloud primitives for the win
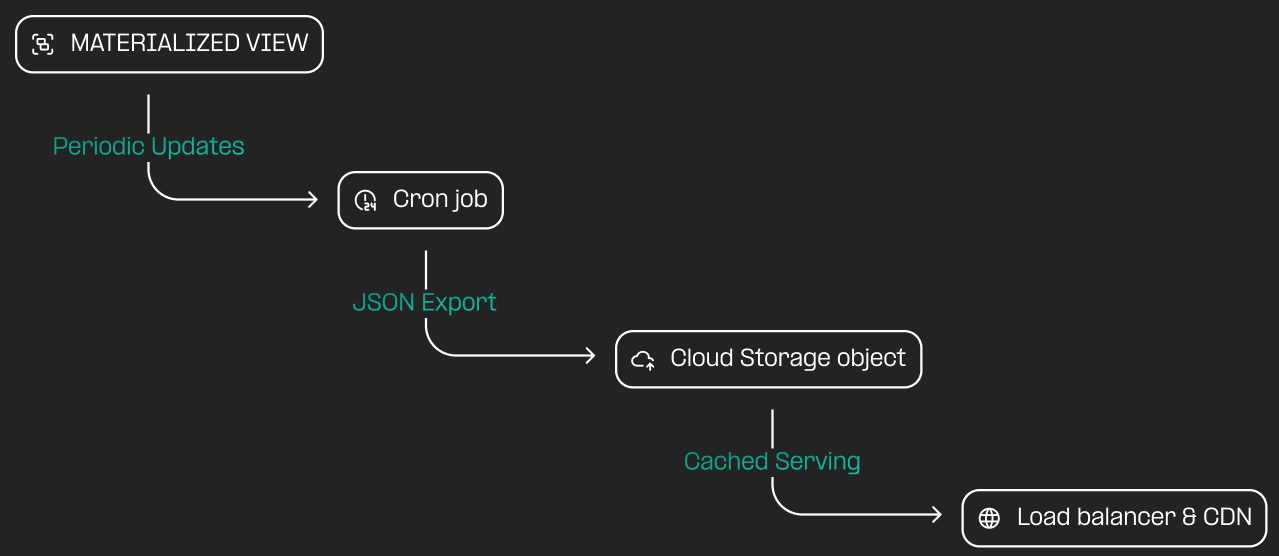
Luckily, we have several core tools to help us build a data product exactly tailored to our needs. Rather than pursue extreme measures to make this work within our existing API, we were able to easily build a data pipeline that removed almost all operational burden.
- Use a
MATERIALIZED VIEWin our PostgreSQL database: this allows us to pay the cost of running the expensive SQL query once, but as close to the data as possible (i.e. directly in the DB). - Periodic export to Cloud Storage: as the economic metrics are updated
throughout the day, we query the
MATERIALIZED VIEWand create a JSON response that we can serve via Cloud Storage to power frontends that visualize the data. - CDN for caching: once the data is in a Google Cloud Storage bucket, we front it with a Google Cloud Load Balancer that provides CDN functionality. This way the data can be loaded again and again with zero load on ANY of our infrastructure.
What's more, we were able to specify 100% of this infrastructure as code with Terraform. This immediately paid dividends when we expanded from one index (ALUR) to many (RISE) because we were able to re-use all of the same primitives without having to revisit any of the decisions.
Conclusion
I spent approximately one full day turning this over in my mind trying to figure out how we could avoid accidentally taking down production to make this work. The breakthrough came from one phrase from the inimitable Matt Blair4:
We need something to just cache the heck out of this
Once I heard that, my mind instantly went to CDN, and the last piece of the puzzle was in place!
When architecture and tooling are well-considered, tasks like this become
simple, freeing operations teams from unnecessary stress. By utilizing cloud
primitives, we didn't need to run a new service, reinvent caching strategies, or
go deep in any other direction. By using the MATERIALIZED VIEW, we avoided
having to worry about spinning up a new system for dealing with data outside of
the application (e.g., a data lake) and the problems that would come with it
(e.g., production hardening, observability, etc.)
This is absolutely a case of work smarter, not harder!